Frequency Analysis: Breaking the Code
We have seen that there are too many possible keys to try in a brute force attack in the Mixed Alphabet Cipher, and given that we could also use symbols in our substitution, there are infinitely many different keys for a Monoalphabetic Substitution Cipher. Despite this, however, every single example of this type of cipher is easily broken, using a single method that works on all of them: Frequency Analysis.
Below we shall discuss the method for implementing Frequency Analysis, and then we shall work through an extended example, to fully appreciate how it works.
The Method
The methodology behind frequency analysis relies on the fact that in any language, each letter has its own personality. The most obvious trait that letters have is the frequency with which they appear in a language. Clearly in English the letter "Z" appears far less frequently than, say, "A". In times gone by, if you wanted to find out the frequencies of letters within a language, you had to find a large piece of text and count each frequency. Now, however, we have computers that can do the hard work for us. But in fact, we don't even need to do this step, as for most languages there are databases of the letter frequencies, which have been calculated by looking at millions of texts, and are thus very highly accurate.
The methodology behind frequency analysis relies on the fact that in any language, each letter has its own personality. The most obvious trait that letters have is the frequency with which they appear in a language. Clearly in English the letter "Z" appears far less frequently than, say, "A". In times gone by, if you wanted to find out the frequencies of letters within a language, you had to find a large piece of text and count each frequency. Now, however, we have computers that can do the hard work for us. But in fact, we don't even need to do this step, as for most languages there are databases of the letter frequencies, which have been calculated by looking at millions of texts, and are thus very highly accurate.
From these databases we find that "E" is the most common letter in English, appearing about 12% of the time (that is just over one in ten letters is an "E"). The next most common letter is "T" at 9%. The full frequency list is given by the graph below.
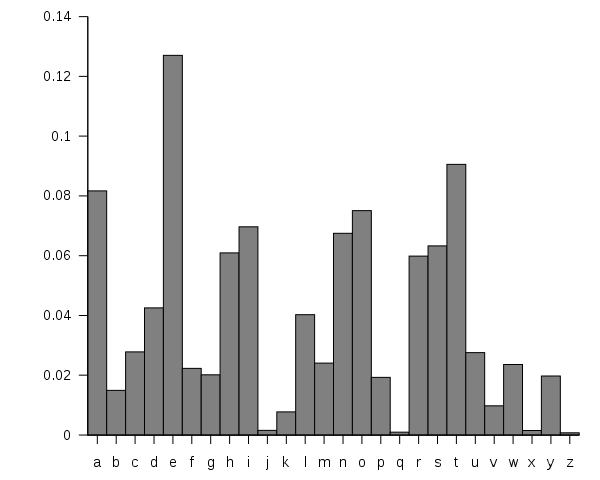
This chart shows the frequencies with which each letter appears in the English language. It clearly shows that "e" is the most common, followed by a small cluster of other common letters.
|
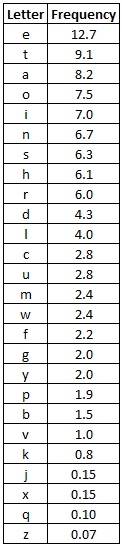
The frequencies of letters appearing in the English language, in order from most common to least.
|
We can use this information to help us break a code given by a Monoalphabetic Substitution Cipher. This works because, if "e" has been encrypted to "X", then every "X" was an "e". Hence, the most common letter in the ciphertext should be "X".
Thus, if we intercept a message, and the most common letter is "P", we can guess that "P" was used to encrypt "e", and thus replace all the "P"'s with "e". Of course, not every text has exactly the same frequency, and as seen above, "t" and "a" have high frequencies too, so it could be that "P" was one of those. However, it is unlikely to be "z" as this is rare in the English Language. By repeating this process we can make good progress in breaking a message.
If we were to just put all the letters in order, and replace them as in the frequencies, it would likely produce jibberish. The codebreaker has to use other "personality traits" of the letters to decrypt the message. This may include looking at common pairs of letters (or digraphs): there aren't many 2 letter words; there are only a few letters which appear as doubles (SS, EE, TT, OO and FF being the most common). There are only two sensical words made of a single letter in English. Other common words also start to appear as you make some substitutions. For example "tKe" might appear frequently after making substitutions for "t" and "e". This is very likely to be "the", a very common word in English. There is a list of useful statistics for the english language available here.
The process of frequency analysis uses various subtle properties of the language, and for this reason, it is near impossible to have a computer do all the work. Inevitably, an element of human input is necessary in this process to make educated decisions about which letters to substitute.
Worked example
In this example we shall use Frequency Analysis to break the code used to encrypt the intercept given below, given that it has been encrypted with a Monoalphabetic Substitution cipher.
In this example we shall use Frequency Analysis to break the code used to encrypt the intercept given below, given that it has been encrypted with a Monoalphabetic Substitution cipher.
GFS WMY OG LGDVS MF SFNKYHOSU ESLLMRS, PC WS BFGW POL DMFRQMRS, PL OG CPFU M UPCCSKSFO HDMPFOSXO GC OIS LMES DMFRQMRS DGFR SFGQRI OG CPDD GFS LISSO GK LG, MFU OISF WS NGQFO OIS GNNQKKSFNSL GC SMNI DSOOSK. WS NMDD OIS EGLO CKSJQSFODY GNNQKKPFR DSOOSK OIS 'CPKLO', OIS FSXO EGLO GNNQKKPFR DSOOSK OIS 'LSNGFU' OIS CGDDGWPFR EGLO GNNQKKPFR DSOOSK OIS 'OIPKU', MFU LG GF, QFOPD WS MNNGQFO CGK MDD OIS UPCCSKSFO DSOOSKL PF OIS HDMPFOSXO LMEHDS. OISF WS DGGB MO OIS NPHISK OSXO WS WMFO OG LGDVS MFU WS MDLG NDMLLPCY POL LYEAGDL. WS CPFU OIS EGLO GNNQKKPFR LYEAGD MFU NIMFRS PO OG OIS CGKE GC OIS 'CPKLO' DSOOSK GC OIS HDMPFOSXO LMEHDS, OIS FSXO EGLO NGEEGF LYEAGD PL NIMFRSU OG OIS CGKE GC OIS 'LSNGFU' DSOOSK, MFU OIS CGDDGWPFR EGLO NGEEGF LYEAGD PL NIMFRSU OG OIS CGKE GC OIS 'OIPKU' DSOOSK, MFU LG GF, QFOPD WS MNNGQFO CGK MDD LYEAGDL GC OIS NKYHOGRKME WS WMFO OG LGDVS.
The first step is to find the frequency of all the letters appearing in the intercept. For this intercept we get the vaues given in the table below.

The frequency of each letter appearing in the above intercept.

The above frequencies ordered from most common to least to make comparisons easier.
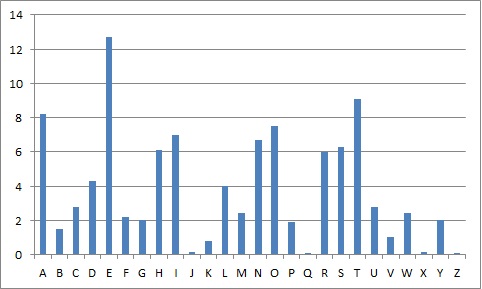
The Standard English Letter Frequencies.
|
The letter frequencies of the letters in the ciphertext.
|
Now that we have all the frequencies of ciphertext letters, we can start to make some substitutions. We see that the most common ciphertext letter is "S", closely followed by "O". From the chart and table above, we can guess that these two letters represent "e" and "t" respectively, and after making these substitutions we get:
GFe WMY tG LGDVe MF eFNKYHteU EeLLMRe, PC We BFGW PtL DMFRQMRe, PL tG CPFU M UPCCeKeFt HDMPFteXt GC tIe LMEe DMFRQMRe DGFR eFGQRI tG CPDD GFe LIeet GK LG, MFU tIeF We NGQFt tIe GNNQKKeFNeL GC eMNI DetteK. We NMDD tIe EGLt CKeJQeFtDY GNNQKKPFR DetteK tIe 'CPKLt', tIe FeXt EGLt GNNQKKPFR DetteK tIe 'LeNGFU' tIe CGDDGWPFR EGLt GNNQKKPFR DetteK tIe 'tIPKU', MFU LG GF, QFtPD We MNNGQFt CGK MDD tIe UPCCeKeFt DetteKL PF tIe HDMPFteXt LMEHDe. tIeF We DGGB Mt tIe NPHIeK teXt We WMFt tG LGDVe MFU We MDLG NDMLLPCY PtL LYEAGDL. We CPFU tIe EGLt GNNQKKPFR LYEAGD MFU NIMFRe Pt tG tIe CGKE GC tIe 'CPKLt' DetteK GC tIe HDMPFteXt LMEHDe, tIe FeXt EGLt NGEEGF LYEAGD PL NIMFReU tG tIe CGKE GC tIe 'LeNGFU' DetteK, MFU tIe CGDDGWPFR EGLt NGEEGF LYEAGD PL NIMFReU tG tIe CGKE GC tIe 'tIPKU' DetteK, MFU LG GF, QFtPD We MNNGQFt CGK MDD LYEAGDL GC tIe NKYHtGRKME We WMFt tG LGDVe.
We now notice that the word "tIe" is appearing frequently in the passage. In English, the most common 3 letter word is "the" and this fits with what we have already done, which suggests that "I" should be decrypted to "h".
Also, by looking at the frequencies again, we see the next most common letter is "G", which is probably one of "a", "i" or "o". We see that the third word is "tG", and the only one of these options that makes sense is "to", so we guess "G" is "o".
oFe WMY to LoDVe MF eFNKYHteU EeLLMRe, PC We BFoW PtL DMFRQMRe, PL to CPFU M UPCCeKeFt HDMPFteXt oC the LMEe DMFRQMRe DoFR eFoQRh to CPDD oFe Lheet oK Lo, MFU theF We NoQFt the oNNQKKeFNeL oC eMNh DetteK. We NMDD the EoLt CKeJQeFtDY oNNQKKPFR DetteK the 'CPKLt', the FeXt EoLt oNNQKKPFR DetteK the 'LeNoFU' the CoDDoWPFR EoLt oNNQKKPFR DetteK the 'thPKU', MFU Lo oF, QFtPD We MNNoQFt CoK MDD the UPCCeKeFt DetteKL PF the HDMPFteXt LMEHDe. theF We DooB Mt the NPHheK teXt We WMFt to LoDVe MFU We MDLo NDMLLPCY PtL LYEAoDL. We CPFU the EoLt oNNQKKPFR LYEAoD MFU NhMFRe Pt to the CoKE oC the 'CPKLt' DetteK oC the HDMPFteXt LMEHDe, the FeXt EoLt NoEEoF LYEAoD PL NhMFReU to the CoKE oC the 'LeNoFU' DetteK, MFU the CoDDoWPFR EoLt NoEEoF LYEAoD PL NhMFReU to the CoKE oC the 'thPKU' DetteK, MFU Lo oF, QFtPD We MNNoQFt CoK MDD LYEAoDL oC the NKYHtoRKME We WMFt to LoDVe.
The first word is now "oFe", which when considered with the appearance of "theF", leads us to the conclusion that "F" is "n". This also fits in with the frequencies of both letters in the tables.
In the third line we see the word "Lheet", which is most likely to be "sheet", and so we replace "L" with "s". Again, the frequencis of these two letters are about right.
one WMY to soDVe Mn enNKYHteU EessMRe, PC We BnoW Pts DMnRQMRe, Ps to CPnU M UPCCeKent HDMPnteXt oC the sMEe DMnRQMRe DonR enoQRh to CPDD one sheet oK so, MnU then We NoQnt the oNNQKKenNes oC eMNh DetteK. We NMDD the Eost CKeJQentDY oNNQKKPnR DetteK the 'CPKst', the neXt Eost oNNQKKPnR DetteK the 'seNonU' the CoDDoWPnR Eost oNNQKKPnR DetteK the 'thPKU', MnU so on, QntPD We MNNoQnt CoK MDD the UPCCeKent DetteKs Pn the HDMPnteXt sMEHDe. then We DooB Mt the NPHheK teXt We WMnt to soDVe MnU We MDso NDMssPCY Pts sYEAoDs. We CPnU the Eost oNNQKKPnR sYEAoD MnU NhMnRe Pt to the CoKE oC the 'CPKst' DetteK oC the HDMPnteXt sMEHDe, the neXt Eost NoEEon sYEAoD Ps NhMnReU to the CoKE oC the 'seNonU' DetteK, MnU the CoDDoWPnR Eost NoEEon sYEAoD Ps NhMnReU to the CoKE oC the 'thPKU' DetteK, MnU so on, QntPD We MNNoQnt CoK MDD sYEAoDs oC the NKYHtoRKME We WMnt to soDVe.
We see the world "soDVe", which could be "solve", implying the transformations of "D" and "V" to "l" and "v" respectively.
In the second line we now have the phrase "one sheet oK so", which suggests that "K" is "r".
one WMY to solve Mn enNrYHteU EessMRe, PC We BnoW Pts lMnRQMRe, Ps to CPnU M UPCCerent HlMPnteXt oC the sMEe lMnRQMRe lonR enoQRh to CPll one sheet or so, MnU then We NoQnt the oNNQrrenNes oC eMNh letter. We NMll the Eost CreJQentlY oNNQrrPnR letter the 'CPrst', the neXt Eost oNNQrrPnR letter the 'seNonU' the ColloWPnR Eost oNNQrrPnR letter the 'thPrU', MnU so on, QntPl We MNNoQnt Cor Mll the UPCCerent letters Pn the HlMPnteXt sMEHle. then We looB Mt the NPHher teXt We WMnt to solve MnU We Mlso NlMssPCY Pts sYEAols. We CPnU the Eost oNNQrrPnR sYEAol MnU NhMnRe Pt to the CorE oC the 'CPrst' letter oC the HlMPnteXt sMEHle, the neXt Eost NoEEon sYEAol Ps NhMnReU to the CorE oC the 'seNonU' letter, MnU the ColloWPnR Eost NoEEon sYEAol Ps NhMnReU to the CorE oC the 'thPrU' letter, MnU so on, QntPl We MNNoQnt Cor Mll sYEAols oC the NrYHtoRrME We WMnt to solve.
In the middle of the second line we have the word "enoQRh", which is likely to be "enough", and so we have the transformations "Q" and "R" to "u" and "g" respectively.
one WMY to solve Mn enNrYHteU EessMge, PC We BnoW Pts lMnguMge, Ps to CPnU M UPCCerent HlMPnteXt oC the sMEe lMnguMge long enough to CPll one sheet or so, MnU then We Nount the oNNurrenNes oC eMNh letter. We NMll the Eost CreJuentlY oNNurrPng letter the 'CPrst', the neXt Eost oNNurrPng letter the 'seNonU' the ColloWPng Eost oNNurrPng letter the 'thPrU', MnU so on, untPl We MNNount Cor Mll the UPCCerent letters Pn the HlMPnteXt sMEHle. then We looB Mt the NPHher teXt We WMnt to solve MnU We Mlso NlMssPCY Pts sYEAols. We CPnU the Eost oNNurrPng sYEAol MnU NhMnge Pt to the CorE oC the 'CPrst' letter oC the HlMPnteXt sMEHle, the neXt Eost NoEEon sYEAol Ps NhMngeU to the CorE oC the 'seNonU' letter, MnU the ColloWPng Eost NoEEon sYEAol Ps NhMngeU to the CorE oC the 'thPrU' letter, MnU so on, untPl We MNNount Cor Mll sYEAols oC the NrYHtogrME We WMnt to solve.
We have the word "Nount" which is could be "count" and "EessMge" which is likely to be "message", giving us that "N", "E" and "M" and "c", "m" and "a".
one WaY to solve an encrYHteU message, PC We BnoW Pts language, Ps to CPnU a UPCCerent HlaPnteXt oC the same language long enough to CPll one sheet or so, anU then We count the occurrences oC each letter. We call the most CreJuentlY occurrPng letter the 'CPrst', the neXt most occurrPng letter the 'seconU' the ColloWPng most occurrPng letter the 'thPrU', anU so on, untPl We account Cor all the UPCCerent letters Pn the HlaPnteXt samHle. then We looB at the cPHher teXt We Want to solve anU We also classPCY Pts sYmAols. We CPnU the most occurrPng sYmAol anU change Pt to the Corm oC the 'CPrst' letter oC the HlaPnteXt samHle, the neXt most common sYmAol Ps changeU to the Corm oC the 'seconU' letter, anU the ColloWPng most common sYmAol Ps changeU to the Corm oC the 'thPrU' letter, anU so on, untPl We account Cor all sYmAols oC the crYHtogram We Want to solve.
It is likely that "W"->"w", "X"->"x", "Y"->"y" and "Z"->"z".
The word "occurrPng" is clearly meant to read "occurring", and it is likely that "sYmAol" is "symbol".
one way to solve an encryHteU message, iC we Bnow its language, is to CinU a UiCCerent Hlaintext oC the same language long enough to Cill one sheet or so, anU then we count the occurrences oC each letter. we call the most CreJuently occurring letter the 'Cirst', the next most occurring letter the 'seconU' the Collowing most occurring letter the 'thirU', anU so on, until we account Cor all the UiCCerent letters in the Hlaintext samHle. then we looB at the ciHher text we want to solve anU we also classiCy its symbols. we CinU the most occurring symbol anU change it to the Corm oC the 'Cirst' letter oC the Hlaintext samHle, the next most common symbol is changeU to the Corm oC the 'seconU' letter, anU the Collowing most common symbol is changeU to the Corm oC the 'thirU' letter, anU so on, until we account Cor all symbols oC the cryHtogram we want to solve.
We can now see that "C" is "f", "B" is "k", "U" is "d", "J" is "q" and "H" is "p".
one way to solve an encrypted message, if we know its language, is to find a different plaintext of the same language long enough to fill one sheet or so, and then we count the occurrences of each letter. we call the most frequently occurring letter the 'first', the next most occurring letter the 'second' the following most occurring letter the 'third', and so on, until we account for all the different letters in the plaintext sample. then we look at the cipher text we want to solve and we also classify its symbols. we find the most occurring symbol and change it to the form of the 'first' letter of the plaintext sample, the next most common symbol is changed to the form of the 'second' letter, and the following most common symbol is changed to the form of the 'third' letter, and so on, until we account for all symbols of the cryptogram we want to solve.
This is an extract from "A Manuscript on Deciphering Cryptographic Messages", by Al-Kindi, from around 850AD, which is the earliest known description of the process of frequency analysis.
We can also now recover the key used in the encryption by putting together the ciphertext alphabet. This is useful if we have other messages intercepted from the same person, as it is likely that they will be using the same key (or a rotation of two or three keys). The key in this case was manuscript.

The reconstructed ciphertext alphabet reveals the keyword.
Discussion
Although Frequency Analysis works for every Monoalphabetic Substitution Cipher (including those that use symbols instead of letters), and that it is usable for any language (you just need the frequency of the letters of that language), it has a major weakness.
Although Frequency Analysis works for every Monoalphabetic Substitution Cipher (including those that use symbols instead of letters), and that it is usable for any language (you just need the frequency of the letters of that language), it has a major weakness.
That weakness is that for short pieces of ciphertext, the cryptanalyst does not have enough data for the sample to relate to the published letter frequencies, and because of this, the frequencies in a small text may be hugely distorted.
Another example that might affect the letter frequencies of a text is the subject matter of the text. If the message is about "zebras" then there is likely to be a lot more "z"s in the plaintext than in a normal piece of writing. This can mess up the Frequency Analysis, but is easily overcome by the other techniques employed.
There are also certain texts that have been written which deliberately skew the frequency of the letters in the plaintext. A very extreme example of this is La Disparition by Georges Perec. This 300 page book was written in 1969, and contains no occurrence of the letter "e", except for the name of the author. It was translated to English in 1995 with the title A Void by Gilbert Adair, under the same constraints. Although not common, it is a warning to cryptanalysts that the personality of a language can be forcibly changed in a piece of writing, and to take note of more than just a single trait (ie frequency) when trying to break a code.
Finally, if the intercepted message has used an extended alphabet including punctuation and digits, then you would need to find the frequencies of the other parts of the alphabet. Punctuation is fairly standard, and clearly the space character is by far the most common character. But the digits appearance will vary hugely depending on the context of the text. This added level of difficulty can make the decryption process take longer (as would removing all the punctuation), but the reality is that the ciphers are still easily broken with a little bit of thought and patience.